


 USA
USA
 UK
UK
 Canada
Canada
 France
France
 Germany
Germany
 Italy
Italy
 Spain
Spain



Data Science at Work is a new series from C1 Insights where we'll be featuring in-depth stories about Data Science in practice at some of the world's most exciting employers. Posts will highlight problems solved with Data Science, what makes these companies 'career destinations', and even ways you can join them.
When it comes to putting data science to work, no one serves their customers better than trivago. That's why we reached out to three of their team members to learn more about their organization and perhaps help some of our readers land a Data Scientist or Data Analyst role at the company. Enjoy!
About trivago
trivago was conceptualized in 2005 in Düsseldorf, Germany by three university friends: Rolf Schr̦mgens, Peter Vinnemeier and Stephan Stubner. Like most start-ups, the site's first iteration was deployed from a garage. In 2006 Stephan decided to become a professor, so Malte Siewert joined the founding team. Today, trivago's management board consists of CEO Rolf Schr̦mgens, CFO Axel Hefer and COO Johannes Thomas.
With just €1.4m initial investment, trivago has grown into one of Europe's most notable unicorns, with a circa €8bn in valuation. What was once a website only available in Germany, built by 3 guys in a garage, now operates in 55 global markets and employs over 1,200+ people.
The secret behind trivago's atypical success is not only attributed to a focus on machine learning and artificial intelligence, but also to a company culture built on human learning and emotional intelligence. This balance continues to attract the best talent from every corner of the globe.
 is hiring!
is hiring!
EXPLORE THEIR DATA SCIENCE JOBS ▶
Meet the Team Members
Andrea Fernández, User Profiling-Data Science Lead, joined trivago January 2014
My undergrad education started in the UK where I studied Mathematics. I then went on to do a PhD in Applied Mathematics, modeling chemical reactions before moving to Germany and starting my industry career at trivago. I have been at trivago 5.5 years. I started as a business analyst for PR releases. After 1.5 years I moved into SEM where I specialized in bidding algorithms and moved into a leadership role overseeing the Marketing algorithms team. In March, I decided to take another jump from Marketing to Product. As part of product, I am responsible for the data science and analytics team in user profiling, focusing on personalization. At trivago, I am also involved in talent leadership.
Sheetij Jain, User Profiling-Product Manager, joined trivago January 2018
Even with a background in Electronics and Communication, it was difficult for me to resist jumping on the 'Data Analytics' stream. Data is the new oil they say, and five years ago I started my quest to do more work with this vital resource. Over that period, I got the opportunity to work as an analytics consultant for multiple companies - Microsoft, T-Mobile and Cisco before working at Amazon as a Data Analyst, then ultimately joining Trivago as a Data Analyst. With a mindset to productize powerful algorithms to deliver better user experiences, I made the switch to Product Management. As a Product Manager on the User Profiling Team, I work with diverse Engineering and Data Science teams to supercharge our hotel search product with personalization.
James Neaves, Hotel Search-Business Intelligence Lead, joined trivago June 2015
I have an educational background in mathematics and history, so data science and analytics was not necessarily an obvious choice. Before working at trivago I started my career at the NHS in the UK, before moving into data analytics for university management at Cardiff and Bristol Universities. Four years ago, I made the jump from the academic to the business world, starting as a data analyst for our website and apps at trivago. Since then, I have developed into a team and strategic leadership role, leading the team responsible for user behaviour analysis and a/b testing for our core products. Alongside my team lead role, I am also involved in strategic leadership within the organization both for company strategy and talent leadership.
What is it like working at trivago - both on the data science team, and at the company more generally?
James Neaves: At trivago, data is at the heart of everything we do. This was apparent to me from my first days at the organization. We have really flat hierarchies and even as a junior data analyst, I was involved in discussions with senior leaders at the company who deeply understood the power of data.
I enjoy my work because it's meaningful, and I have the ability to make an impact, free from organizational roadblocks. Decisions at trivago are made using data and insights, so as soon as I can prove I am going in the right direction, I get the support I need. The company also encourages personal development, internal growth, and job rotations.
We also move fast! When we make decisions, we do it with confidence and put our full energy behind it. This was a big contrast to the traditional annual cycles of the academic calendar.
As an organization, we have six core values- (1) trust, (2) authenticity, (3) entrepreneurial passion, (4) power of proof, (5) unwavering focus and (6) fanatic learning.
In my opinion, Fanatic Learning is what allows data science to drive the business forward. Our team is involved in so many key areas including product testing, marketing spend experimentation, hotel search, marketplace, and advertiser relations. This shows that as an organization, we value data, learning, and experimentation, while also giving team members at all levels the ability to make a real impact.
Andrea Fernández: I agree and would add more detail to James' point on Fanatic Learning — specifically about the exchange of information across different data science teams throughout the company.
We have several initiatives that originated from individual team members — created by data scientists for data scientists. We also have several specialized guilds in different subjects as well as a more general "meetup" where team members from different departments get the opportunity to present learnings and projects.
What's the biggest difference between data science in academia vs data science on-the-job?
Andrea: Business is faster-paced, less structured, and more hands-on than academia.
At work, a more pragmatic approach is needed in which one needs to understand the tradeoff between complexity and impact. One should not be afraid to take a more iterative approach, pushing one version at a time, rather than waiting until all the research is done before presenting findings or making crucial decisions.
Another distinction between research and academia is the ground data. Although I believe this is changing, industry datasets tend to have more hiccups, outliers and bugs. When analyzing or building models in industry, one needs to be pragmatic and develop techniques to deal with inconsistencies and data that isn't clean. In research, however, the outlier is sometimes the most interesting part worth researching.
James: From my experience, the largest skill gap is related to the practical application of data science theory. Our data scientists cannot just focus on building the most accurate model or the best prediction. They must also consider the impact on the business.
At trivago, we try to remain conscious of opportunity costs and return-on-investment. While we encourage failure and fully embrace trial and error, we need to be comfortable dropping projects that don't show promise while doubling down on projects that do. Understanding the practical impact of data science work is an incredibly valuable skill in becoming an effective team member.
When recruiting, I often look for candidates who have at least one year of experience (including internships), to help bridge this gap. The good news? Most people pick up the 'business impact' concept pretty quickly once they begin working.
What is trivago's unique approach to problem solving?
Sheetij Jain: Data is absolutely our most valuable resource when it comes to solving problems.
Once we identify an opportunity, we develop an idea, then substantiate it with data points to truly understand the depth of the problem. Once we have the problem prioritized, we "build a skateboard" instead of thinking about the entire car (see image below). With data science projects in particular, we've learned the importance of providing value at small intervals (in smaller shipments) as opposed to waiting too long to get feedback on our models.
Here's what we mean by building a skateboard before working on the whole car:
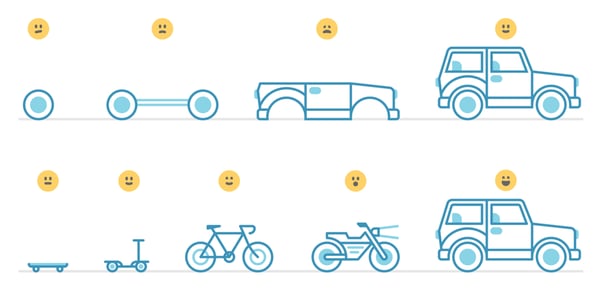
The skateboard is our MVP (Minimum Viable Prototype) that we use to test and gather valuable feedback for future iterations. This is how we approached our most recent project "Concept Recommender" - where the first version of the recommender was based on analysis and a naive model to understand the potential impact of solving this problem. Once we understood the potential impact and gathered the necessary feedback and data from users, it was time to iterate and get closer and closer to our dream car!
What is Concept Recommender? How did it go from idea to feature? What were the results?
Sheetij: Concept Recommender powers trivago's 'More Filters' section:

This feature provides users a personalized recommendation of the hotel amenities ("concepts" as we call them) taking a user's context into consideration.
Before this feature went live, our recommendations were based on intuition and business rules. We replaced that old business logic with the power of an algorithm.
Why was this feature so important?
Sheetij: Users can choose from hundreds of hotels on trivago, even after limiting their search to a specific destination. This makes it difficult for users to filter search results based on their favorite amenities and what different destinations have to offer. Our ‘Concept Recommender’ solves this by delivering a personalized list of hotel amenities to help users get a more relevant, refined list of trip options.
How did you build it? Is it still being worked on?
Sheetij: We took this feature through four steps (1) data analysis, (2) data collection, (3) analysis & model building, and (4) testing. Here's a detailed recap of the process:
Data Analysis:
We started off with an analysis of the hotel amenities (concepts) we exposed to users and the selections they made. The analysis highlighted that very few concepts were ever selected. This helped us understand the 'Presentation Bias' effect ─ which resulted in users primarily selecting the concepts that were put in front of them. At this stage, we learned we didn't have enough data to fully understand user preferences.
Data Collection:
As a data-driven company, we gather data when we don't have enough to work with. Therefore, we needed to start with a new test to collect an unbiased dataset on user-concept preferences. We chose 'n' concepts randomly from a pool of all concepts, then exposed those concepts to users. We now had more than enough data to actually model user preferences on concept selection.
Analysis & Model Building:
With loads of new data, we kickstarted a new round of analysis to understand the results of the test. Insights from the analysis indicated we should take a closer look at 'Platform' (German platform ─ trivago.de, UK platform ─ trivago.co.uk, etc.) for enhancing concept recommendations. Thus, we built a linear model to output the top 15 concepts personalized per platform. We weren't sure how well this would work, but we were excited to see the results.
Testing:
Once we had the model ready, we engineered the API to deliver the model output so that users could begin to see and respond to the concepts our model was recommending. We identified two key performance indicators (KPIs) to track the effectiveness of our new concept recommender's performance:
- Selection-to-Visible (S2V): Number of users who select concepts, of all users who opened the 'More Filters' interface
- CO after concept selection: Number of users who click on hotels after selecting concepts
Results:
We knew conceptually that personalization, delivering more relevant recommendations, would drive business results - but the massive increase we saw surprised us. Our Data Science team worked on creating a dashboard to track our concept recommender's daily performance. By adding "platform" as context for recommending concepts, we increased refinement (concept selection) by 30%!
The Future:
Despite the excitement around concept recommender, we're still just scratching the surface with regard to what can be achieved using data science to deliver more personalization and relevance to our users.
We are currently considering 'User Personality' ─ what Germans like vs. what Indians like, as well as 'Destination Personality' ─ which considers the destination of the trip and 'Trip Type' ─ Weekend, Weekday, Family trip, etc.
How do you communicate results on projects like these up the org chart and across departments?
James: Communicating around data science projects can take many forms and we have different forums for this. We respect data science as a key competency within trivago and increasingly it is at the heart of many key initiatives. In Hotel Search, we often highlight the work of data science teams in our quarterly 'all hands' presentations or in our weekly meetups, which are open to everyone from product owners to designers to software engineers.
Outside of our routine business communication, we also have data science and analytic groups dedicated to certain topics, such as machine learning or language specific groups such as python or R. These groups collaborate on different topics and meet semi-regularly to discuss projects, applications of their work and best practices. Internally, these groups are referred to as 'guilds'. As a learning organization, cross-department knowledge exchange is really important in getting the most out of our collective experience.
We also reach out to the data science community outside of the organization. We run events such as the data science after work, which we have hosted at our campus where we've shared insights into the projects we work on with data scientists outside the organization, both in industry and academia. This is also a great opportunity for our people to grow and practice their presentation skills in a familiar environment.
What skills, characteristics, and attributes is trivago looking for in new data science hires?
James: Obviously, keen analytical ability and data science skills are important for us though we can be flexible with regard to technical skills. For example, on my team I have people using both python and R. I try to encourage all of us to grow as a team and continually invest in professional development and acquiring new skills.
There are some additional characteristics I look for when hiring, that may not be quite as standard. I am interested in finding people with strong communication skills. Our data science people must often work with product owners and business stakeholders. In these cases, knowing the technical side of data science is not enough, you must also be able to discuss results in a way that non-experts can understand. Great communication skills can turn data into truly actionable insights.
Another aspect that is important is fit within the company. In data science, I see three of our core values that really resonate with exceptional data science talent fanatic learning, power-of-proof and entrepreneurial passion. While the benefits of a data-driven approach and continual learning may be quite clear, our entrepreneurial passion value means we should all take an ownership and business-oriented approach to the projects we work on while maintaining passion for the work we are doing.
Andrea: Specific data science skills I look for can be broken down into 5 areas. All these should be more or less present and not all are expected to be developed to the same extent. A good team would be able to complement each other in these areas.
- Visualisation - This is inline with James' comments regarding communication skills. It is important to be able to present and communicate results and insights in an understandable way so all audiences can follow and act.
- Programming skills - Capability to embrace and learn different programing languages to analyse and create models.
- Data Wrangling/ETL Skills: Getting data to a usable format is a challenge in and of itself.
- Modelling: Application and evaluation of different models such as machine learning models.
- Math and Stats: Ground knowledge of the theory behind models and evaluation/testing methods.
Regarding "soft" skills, I totally agree with James. Entrepreneurial passion and willingness to connect data science with business impact is also vital.
When people join the trivago team, what can they expect?
- Growth: We help you grow as trivago grows through support for personal and professional development, constant new challenges, regular peer-feedback, mentorship and world-class training.
- Autonomy: Every talent has the ability to make an impact independently by driving topics thanks to our strong entrepreneurial mindset, our horizontal workflow and self-determined working hours.
- International environment: Our agile, international culture and environment with team members from 50+ nations encourages mutual trust and creates a safe space to discuss openly and act freely.
- Collaborative spaces: Our state-of-the-art campus in Düsseldorf offers interactive spaces where we can easily collaborate, exchange ideas, take a break and workout together.
- Relocation: We support our international talent - helping with relocation costs, work permit and visa questions, free language classes, flat search and insurance.
Nice! Are you hiring? If so, tell us about those roles!
Andrea: We are hiring! We're always looking for motivated individuals who want to join an exciting and dynamic environment and see the impact of their work. I might be a bit biased, but for aspiring data scientists, I can't think of a better place to work than trivago!
We are a diverse team from over 50 different countries, headquartered in Düsseldorf, Germany. Some of our data scientists are also based in Amsterdam, Netherlands.
We recruit from all over the world, so please feel free to apply for the role that most appeals to you!
You can find all our data science and analytics open positions here.
is hiring!